Die Nutzung von ChatGPT beim Fremdsprachenlehren und -lernen
Brisant, besorgniserregend, begrüßenswert?
Mein Manuskript zum Impulsvortrag beim Netzwerktreffen aller Sprachenzentren Berlin-Brandenburg am 07.07.2023

Es ist gefühlt noch gar nicht so lange her, dass ich anlässlich des Netzwerktreffens aller Sprachenzentren der Hochschulen in Berlin und Brandenburg einen halbstündigen Impulsvortrag für ca. 90 Kolleginnen und Kollegen gehalten habe. Für mich war es eine sehr besondere Einladung und ich habe mich sehr geehrt gefühlt, in diesem Rahmen sprechen und im Anschluss mit den Teilnehmenden diskutieren zu können.
Wie gesagt, gefühlt ist es noch nicht lange her, realerweise auch erst fünf Monate, aber in Anbetracht der rasanten Entwicklung von Generativen Sprachmodellen und KI-Anwendungen scheint eine lange Zeit zwischen Damals und Jetzt zu liegen. Dennoch möchte ich, wenn auch verspätet, mein Manuskript zum Impulsvortrag hier auf meinem Blog veröffentlichen. Die Zuhörerinnen und Zuhörer beim Netzwerktreffen an der Humboldt-Universität in Berlin waren, wie gesagt, Hochschullehrerinnen und -lehrer für Fremdsprachen. Nichtsdestotrotz sind viele Überlegungen genereller Art und auch die Fragestellungen, die ich in meinem Vortrag aufgeworfen habe, sind nach wie vor gültig. Ich wünsche viel Vergnügen beim Lesen und freue mich immer über Kommentare und Diskussionsbeiträge.

Wir beginnen mit einer sehr simplen und gleichzeitig komplexen Frage: „Warum arbeiten wir als Dozentinnen und Dozenten für Fremdsprachen an Sprachenzentren?” Und was hat das mit ChatGPT zu tun? Dazu eine kurze Geschichte:
1 Und die ganze Erde hatte eine einzige Sprache und dieselben Worte. […] 4 Und sie sprachen: Wohlan, lasst uns eine Stadt bauen und einen Turm, dessen Spitze bis an den Himmel reicht, dass wir uns einen Namen machen, damit wir ja nicht über die ganze Erde zerstreut werden! 5 Da stieg der HERR herab, um die Stadt und den Turm anzusehen, den die Menschenkinder bauten. 6 Und der HERR sprach: Siehe, sie sind ein Volk, und sie sprechen alle eine Sprache, und dies ist [erst] der Anfang ihres Tuns! Und jetzt wird sie nichts davor zurückhalten, das zu tun, was sie sich vorgenommen haben. 7 Wohlan, lasst uns hinabsteigen und dort ihre Sprache verwirren, damit keiner mehr die Sprache des anderen versteht! 8 So zerstreute der HERR sie von dort über die ganze Erde, und sie hörten auf, die Stadt zu bauen. 9 Daher gab man ihr den Namen Babel, weil der HERR dort die Sprache der ganzen Erde verwirrte und sie von dort über die ganze Erde zerstreute.
1.Mose 11,1-9, Schlachter
Wir alle kennen die Geschichte vom Turmbau zu Babel. Und doch kommt mir die Geschichte gerade für unser heutiges Thema doppelt passend vor:
- 1. Ohne die „Zerstreuung“ der Sprachen weg von einer prototypischen Ursprache wären wir heute keine Fremdsprachenlehrer*innen an Sprachenzentren.
- 2. Kann man die rasante Entwicklung und Verbreitung von KI-Tools wie ChatGPT vielleicht als erneuten Versuch der menschlichen Selbstüberhöhung interpretieren?

Die Faszination für intelligente Wesen außerhalb unserer menschlichen Spezies ist wahrscheinlich so alt wie die Menschheit selbst. Ich habe exemplarisch ein paar Beispiele aus Kultur und Literatur mitgebracht, um zu illustrieren, wie wir uns so eine „künstliche Intelligenz“ kulturhistorisch vorstellen können: Da gab es einen vermeintlich selbstspielenden Schach-Automaten, der als Attraktion durch die Weltgeschichte fuhr, aber eine Illusion war. Es gab z.B. das Problem des Zauberlehrlings, der mit einem Zauberspruch die Besen zum Leben erweckt hat, die er plötzlich nicht mehr kontrollieren kann. E.T.A. Hoffmann griff das Sujet in der Erzählung „Der Sandmann“ auf, in dem sich der Protagonist in einen Automaten, also eine künstliche Puppe namens Olimpia verliebt und ihr Menschlichkeit zuschreibt. Kurze Zeit später veröffentlicht Mary Shelley Frankensteins Monster und auch in Goethes Faust II erschafft Wagner einen Homunculus, einen kleinen Mensch aus einem Reagenzglas.

Die Entwicklung künstlicher Intelligenz hat in den 1950er Jahren mit John McCarthy am Dartmouth College begonnen. Seither gab es immer wieder Aufs und Abs, Hochs und Tiefs, Hypes und Enttäuschungen. Die Autorin Melanie Mitchell nennt das auch den Kreislauf von Winter- und Frühlingsphasen. Und nun haben wir seit November letzten Jahres mit ChatGPT wieder eine Frühlingsphase und seither einen anhaltenden Hype um dieses generative Sprachmodell und was es für uns Menschen in unterschiedlichen Lebens- und Arbeitsbereichen bedeuten kann. Und was kann es eigentlich bedeuten?
Wir beginnen also mit der Frage, was wir über unsere Welt wissen.
Wie würden Sie unsere Welt oder unsere Lebensrealität heute charakterisieren?
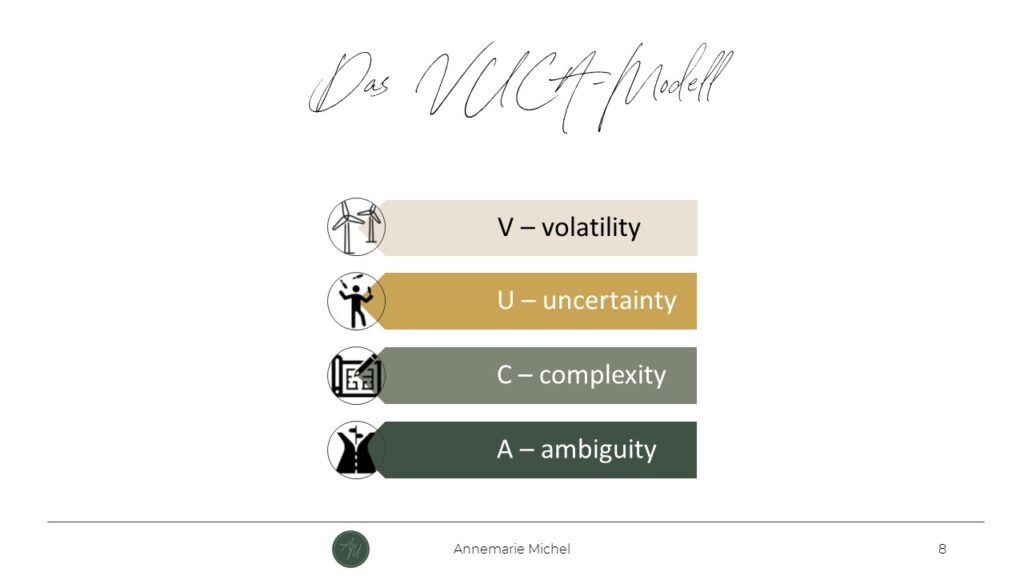
Vielleicht mit Adjektiven wie unbeständig, ungewiss, komplex oder mehrdeutig. Das zumindest steckt hinter dem Akronym des Begriffs “VUCA-Welt”, der unsere moderne Welt und die darin liegenden Schwierigkeiten und Widersprüche beschreibt. Aufgrund dieser Lebensrealität verstehen Bildungsforscherinnen und Pädagogen wie Lisa Rosa oder Nele Hirsch heute den Umgang mit Komplexität als entscheidende zu vermittelnde Kompetenz in Lehr-Lern-Kontexten. Das behalten wir für später im Hinterkopf.
Was wissen wir nun aber über ChatGPT, was daran ist so brisant?
- ChatGPT gehört zum Non-Profit-Mutterunternehmen OpenAI Inc., das eine gewinnorientierte Tochtergesellschaft OpenAI LP hat.
- Zentrale Geldgeber der Organisation sind Elon Musk und Microsoft, weitere Unterstützer sind Reid Hoffman, der Mitbegründer von LinkedIn, Peter Thiel, der Mitbegründer von PayPal, Greg Brockman, der ehemalige Chefentwickler von Stripe, Jessica Livingston, die Gründungspartnerin von Y Combinator), Amazon Web Services und InfoSys. Vorsitzender ist Sam Altman, Präsident von Y Combinator.
Wir wissen, dass die Möglichkeit, mit ChatGPT Texte zu generieren, Auswirkungen auf das Lehren und Lernen haben wird. Wer schreibt hier überhaupt noch? Und wer stellt sicher, dass Inhalte verstanden und selbständig gelernt worden sind? Das wirft die nächste Frage auf:
Was ist ChatGPT genau und wie funktioniert es?
ChatGPT bedeutet Generative pretrained transformer. Das heißt, das Programm wurde darauf trainiert und ist in der Lage, menschliche Sprache zu produzieren. ChatGPT gehört zu den LLM, Large Language Models. Dessen Grundlage bilden unzählige Trainingsdaten aus dem Internet, aus denen ChatGPT durch deep learning selbst „lernt“.

ChatGPT wird, zurückgehend auf ein Paper der Computerlinguistin Emily Bender, auch als stochastischer Papagei bezeichnet. Warum? Weil sie…
- eine anhand von Wahrscheinlichkeiten gestaltete Zusammenstellung von Wörtern sind
- auf dem einprogrammierten Erkennen von Satzstrukturen basieren
- aus riesigen Datenmengen ausgelesen werden,
- deren Ursprung und Zusammensetzung intransparent bleiben,
- in vielen Runden von Ingenieur*innen und Vertragsarbeiter*innenbewertet und annotiert werden
- und sie trotzdem oder gerade deshalb fehleranfällig sind bzw. “halluzinieren”.
Grundsätzlich problematisch bleibt dabei also die Intransparenz, was die Datengrundlage angeht. Ebenso problematisch ist der Eindruck, dass ChatGPT quasi ohne menschliche Einwirkung funktioniert. Dieser Eindruck ist falsch: Diese sich wiederholenden, kleinteiligen Arbeiten und Korrekturschleifen wurden und werden hauptsächlich von Menschen aus dem globalen Süden ausgeführt. Zudem reproduziert ChatGPT biases aus unserer Gesellschaft, eben weil diese biases auch in unserer Gesellschaft und den Trainingsdaten aus dem Internet vorkommen.
ChatGPT hat schon seit seiner Veröffentlichung Auswirkungen auf den Bildungsbereich und auch auf das Fremdsprachenlehren und -lernen, genauer auf 4 umrissene Bereiche: 1) Lehre, 2) wissenschaftliche Arbeiten und Paper, 3) Curricula und 4) Regularien wie Prüfungsordnungen, Modulkataloge etc.
Schauen wir uns nun genauer an, warum wir ChatGPT als besorgniserregend bzw. als begrüßenswert wahrnehmen könnten und warum es so oder so nicht sinnvoll ist, vor der neuen Technologie davonzulaufen oder sie gar zu ignorieren. Besorgniserregend könnten die folgenden Ms sein:
- Menschliche Sprache und Kommunikation
- Mangel & Macht
- Manipulation
1 Menschliche Sprache & Kommunikation
Zuerst zur menschlichen Sprache. Zu Beginn habe ich mich auf den Turmbau zu Babel bezogen und darauf, dass wir als Menschen fasziniert von der Idee sind, ein wie immer geartetes Wesen zu schaffen, das über die gleiche, wenn nicht sogar mehr Intelligenz verfügt als wir.
Wahrscheinlich kennen Sie das 4-Ohren-Modell des Psychologen Friedemann Schulz von Thun. Er geht davon aus, dass Kommunikation im Kern einen Sender, einen Empfänger und eine Nachricht hat. Da wir soziale Wesen sind und uns in einer gemeinsamen Umwelt aufhalten, auf die wir uns sprachlich beziehen, werden neben der Nachricht noch weitere Nachrichten im Subtext gesendet.
Laut Emily Bender, Professorin für Computerlinguistik an der Universität von Washington, findet Kommunikation zwischen Individuen statt,…
- die Gemeinsamkeiten haben und sich dieser Gemeinsamkeiten (und ihres Ausmaßes) bewusst sind,
- die kommunikative Absichten haben, die sie mit Hilfe der Sprache vermitteln, und
- die die mentalen Zustände der anderen während der Kommunikation modellieren.
- Die menschliche Kommunikation beruht also auf der Interpretation der impliziten Bedeutung, die zwischen den Individuen vermittelt wird.
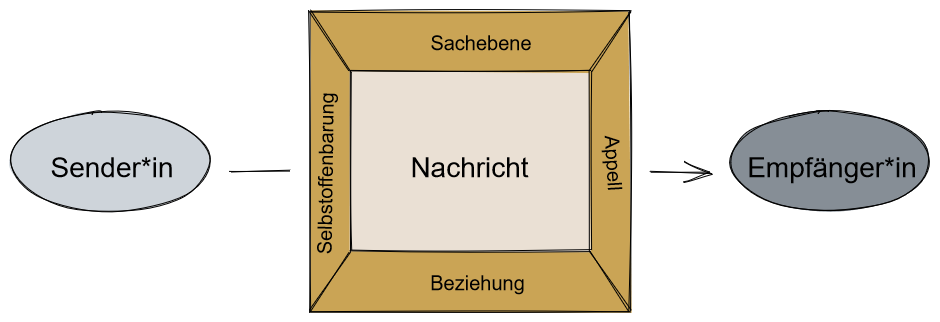
Bei Schulz von Thuns Modell sehen wir z.B. die mitschwingenden Bedeutungen auf der Sachebene, der Beziehungsebene, der Selbstoffenbarungs-Ebene und der Appellebene.
Ein Text, der von einem LLM erzeugt wird, basiert nicht auf einer kommunikativen Absicht, einem Modell der Welt oder einem Modell des Geisteszustandes des Lesers. Das kann auch nicht der Fall sein, denn die Trainingsdaten beinhalteten nie den Austausch von Gedanken mit einem Zuhörer, und die Maschine hat auch nicht die Fähigkeit, dies zu tun. Das Phänomen, dass etwas, nämlich eine Software mit uns in unserer natürlichen Sprache kommuniziert, sich aber nicht in einer gemeinsamen Vorstellung von Welt mit uns befindet, ist sehr neu. Dabei entwickelt sich die Tendenz zu anthrophomorphisieren, laut Duden heißt das „zu vermenschlichen; menschliche Eigenschaften auf Nichtmenschliches [zu] übertragen“. Das hat in der jüngeren Vergangenheit z.B. dazu geführt, dass der Softwareingenieur Blake Lemoine von Google beurlaubt wurde, nachdem er öffentlich bekundet hat, dass das Large Language Model LaMDA von Google ein Bewusstsein und eine Seele habe.
Gerade hier ist unsere Rolle als Lehrkräfte und als Expert*innen für Sprache äußerst wichtig: Wir vermitteln zwischen Sprachen und Kulturen, sind sensibilisiert und Teil eines gemeinsamen gesellschaftlichen Erfahrungsraums. ChatGPT & Co. haben nicht dieselbe interkulturelle Kompetenz und kulturelle Bewusstheit oder das tiefe Verständnis von angemessenem Sprachgebrauch wie wir. ChatGPT und andere KI-Chatbots sind kein Äquivalent zu einer reellen Person, sie haben kein Bewusstsein und im Fall von GPT-3.5 endet sein Sprach- und Informationsvermögen im Jahr 2021. Somit verwendet GPT-3.5 keine lebendige Sprache, sondern das, was bis 2021 im Internet konserviert wurde. Wir müssen dafür sorgen, dass die gedachten und gefühlten Grenzen – Stichwort Anthropomorphisierung – nicht verwischen und dass unsere Lernenden bei der Nutzung von ChatGPT auch dafür sensibilisiert werden.
2 Mangel und Macht
Als Lehrkräfte sollten uns Chancengleichheit und gesellschaftliche Teilhabe wichtig sein. Besorgniserregend ist, dass das Narrativ von Künstlicher Intelligenz ein Marketingmodell und ein profitorientiertes Wettrennen großer Tech-Unternehmen ist. Cui bono? Wem nützt das? Der Markt wächst rasant, fast täglich kommen neue KI-Tools zur Text-, Stimm-, Video- und Bildgenerierung dazu und es fällt schwer, einen Überblick zu behalten.
Die großen Tech-Unternehmen wie Google, Microsoft, Facebook und OpenAI genügend finanzielle Mittel, um Daten zu kaufen und Klick-Worker zu bezahlen, fast eine Monopol-Stellung und damit große Macht. Daher wahren sie sorgsam die Geheimnisse ihrer Datenherkunft und der selbstlernenden Algorithmen. Viel Macht liegt also in den Händen von Wenigen.
Wenn wir die Tools benutzen möchten, werden unsere Daten wiederum dazu verwendet, die Chatbots mit unseren Texten zu füttern, deren Antworten zu raten und zu verbessern. Wie genau unsere Daten verarbeitet und weitergenutzt werden, wird nicht transparent gemacht. Besonders in der Kritik steht auch die Intransparenz, was die Trainingsdaten angeht, die vermutlich größtenteils aus urheberrechtlich geschützten Texten aus dem Internet besteht.
3 Manipulation
Eine Sorge im Bildungsbereich generell ist das disruptive Potenzial von ChatGPT. Wie lehren und lernen wir in Zukunft? Und wie können Leistungen zukünftig überprüft und bewertet werden? Wie kann die Qualität des Lehrens und Lernens angesichts von möglicher Manipulation und Täuschungsversuchen sichergestellt werden? Besorgniserregend dabei ist, dass sicherlich einige Studierende nicht wissen, wie ChatGPT funktioniert, dass die produzierten Texte schlüssig und richtig klingen, aber dennoch voller Desinformation oder Biases sein können und dass ihre eingegebenen Daten zu Trainingszwecken der KI weiterverwendet werden.
In diesem Kontext sollte die Bedeutung von Wissen und Lernen neu verhandelt werden. Was brauchen wir und was brauchen unsere Lernenden, um in der VUCA-Welt zu bestehen, mit Komplexität umzugehen und Informationen richtig einzuordnen? Welche Chancen ergeben sich aus ChatGPT und Co.?
Individualisiertes Lernen 2.0?
Damit komme ich zur Frage, was an ChatGPT begrüßenswert ist.

Hier sehen wir ein Sprachlabor aus den 1970er Jahren. Die Audiolinguale und audiovisuelle Methode waren gerade im Kommen und das Lernen wurde individualisierter. Wie funktioniert Lernen heute mit ChatGPT & Co.? Im Vergleich zum Sprachlabor gibt es weitere Vorteile:
- Studierende können ort- und zeitunabhängig Lernen
- Das Lernangebot ist klar an ihren Motiven und Interessen ausgerichtet
- Das Lernen funktioniert flexibel, interaktiv und mit sofortigem Feedback
Für das Lernen und Lehren kann ChatGPT beim Erlernen von Wortschatz, der Grammatik, beim Leseverstehen, beim Schreiben und der Textproduktion von Vorteil sein. Wir Lehrende können mit ChatGPT & Co. Seminare und Unterricht planen, Ideen sammeln und Brainstormen sowie weiteres Material und Aufgaben erstellen. Alles, was es dazu braucht, sind gute Prompts.
Was sind Prompts?
Als Prompts werden Anfangstexte in der Kommunikation mit Chatbots verstanden; Prompts können Aufforderungen, Anweisungen oder Fragen beinhalten. Je besser, d.h. je komplexer, präziser und zielorientierter ein Prompt formuliert wird, umso besser wird der Output durch die KI. Daher hat sich ein ganz neues Berufsfeld entwickelt, das sog. Prompt Engineering, das zum Ziel hat, Anfangstexte so zu entwerfen und zu überarbeiten, dass man damit optimale Ergebnisse erzielen kann.

Übertragen auf das Lehren und Lernen von Fremdsprachen könnte ein Prompt für Studierende zum Beispiel so aussehen: Spiele den Interviewer und stelle mir [auf XY] Interviewfragen für die Stelle [XY]. Stell mir eine Frage und warte auf meine Antwort. Stell dann eine weitere Frage. Beende das Gespräch, wenn ich sage „Danke für Ihre Zeit“. Gib mir anschließend ein Feedback zu meiner Leistung.
Bei allem Engineering sollten wir aber nicht vergessen: „Technische Entwicklung ist Mittel, nicht Zweck“ Daher möchte ich Ihnen zum Abschluss noch ein paar Impulse von Bildungsforscherinnen und Wissenschaftlerinnen mitgeben.
Zitate zum Schluss…
“Wie immer heißt die Frage: Welche Art von Technik wollen wir? Und bei der Bearbeitung dieser Frage stoßen wir auf die übergeordnete Frage: Welche Art von Gesellschaft wollen wir? Und die nächste Frage lautet dann: Wie kommen wir dahin?“, so Bildungsforscherin Lisa Rosa. Und auch Nele Hirsch macht sich für die pädagogische Perspektive auf KI stark: „In der KI-Debatte kann uns ein Leitbild helfen, pädagogische Interessen stark zu machen. Uns ist dann klar, dass klügere Maschinen pädagogisch nicht per se hilfreich sein werden. Die für uns spannendere Frage ist: (Wie) können Menschen mit diesen Maschinen klüger werden?“
Und zuletzt appelliert Doris Weßels, Wirtschaftsinformatikerin an der FH Kiel, die im März dieses Jahres auch beim Bremer Symposion zum Fremdsprachenlehren und -lernen an Hochschulen gesprochen hat, an uns Hochschullehrende, die 4 As umzusetzen:
- Aufklären, also Informationsveranstaltungen anbieten, um alle Lehrenden ins Boot zu holen.
- Das zweite A: Bitte selbst ausprobieren. […]
- Das dritte A: Akzeptieren. Man muss sich daran gewöhnen, dass das keine Eintagsfliege ist, die morgen wieder weg ist. Das ist irreversibel und wird rasant weitergehen. […]
- Das vierte A: Wenn wir das erlebt haben, wird es automatisch zu einer Diskussion kommen. […] Das bedeutet, wir werden aktiv.
An welchem A stehst du gerade?

Dozentin und Schreibtrainerin in Berlin
Wissenschaftliches und kreatives Schreiben, (Hochschul-)Didaktik
Deutsch als Fremdsprache






{kind=link}